

AI loves data, the more data it has the more accurate the models are which leads to better business outcomes and better research outcomes. A lot of the data today is locked behind closed walls. To unlock the digital economy and to train AI models, you need to unlock private data, that is exactly what Ocean’s Compute-to-Data is doing. It’s unlocking private data while preserving privacy. Join us and Trent McConaghy, Co-Founder of Ocean Protocol, as we discuss how to unlock data in privacy manner in order to monetize it.
Trent has a background in AI and has been working in the real of blockchains for the last several years with a focus on data. His initial work was around IP and data, and then on big data with a blockchain database.
What is blockchain?
A mundane definition of blockchain is that it is a database with three special characteristics: decentralised immutable assets:
- Decentralised as in, no single entity owns or controls it. If for example you have tens of thousands of people running it then it starts to act and look like a public utility just as a gas company or the internet itself. This public utility records “state”.
- Immutable means once you’ve written onto it, it’s there for good. This is very useful characteristic for tracking provenance whether of financial instruments or of a fruit flowing from a farm in one country to a supermarket shelf in another.
- The idea of assets is if you have the private key, or password, to something then you own it. For example, if you have a Bitcoin private key then you own approximately $10,000.
Since that initial inception of blockchain a few new characteristics have been added:
- Smart contracts which are essentially unstoppable scripts that run on top of a blockchain automatically when they have received the appropriate inputs.
- Blockchains are seen as incentive machines to get people to perform certain actions. Bitcoin for example gets people to add to the security the Bitcoin network through hashing, known as Bitcoin mining. People are willing to expend computational power to do this hashing, add security to the network, in the hope of getting paid in Bitcoins by the Bitcoin network.
About Ocean
Ocean Protocol is a decentralized data exchange protocol to unlock data for AI, launched in 2017. Leveraging blockchain technology, Ocean Protocol connects data providers and consumers, allowing data to be shared while guaranteeing traceability, transparency, and trust for all stakeholders involved. It allows data owners to give value to and have control over their data assets without being locked-into any single marketplace.
The data economy
In July 2019, Trent recorded his first podcast with Insureblocks entitled “The Data Economy – Insights from OceanProtocol”. He sees that the data economy is already a true economy in that there is buying and selling of data but the key is that it’s really hard to see it. You could nearly characterise it as a sort of shadow data economy, where there’s buying and selling data, but it’s mostly behind closed doors.
On the one hand it’s visible if you’re buying data feeds from Bloomberg regarding stock prices. On the other a lot of data is bought and sold behind closed doors that you don’t hear about. For example, we don’t hear about the 150 plus organisations that Facebook is buying data from in order to mine people better to sell ads to.
“The more data you sell, the less valuable it becomes. Instead, if you work with privacy-preserving tools and you allow other people to develop applications and derivative products, using your data, without ever giving you a copy of your data to anyone else — you get all the revenue without the increase in supply. This means, whenever someone wants to do anything with this kind of data, you still have billing power. And secondarily, you also have better pricing power,” concludes Andrew Trask
Compute-to-data and extracting value out of private data
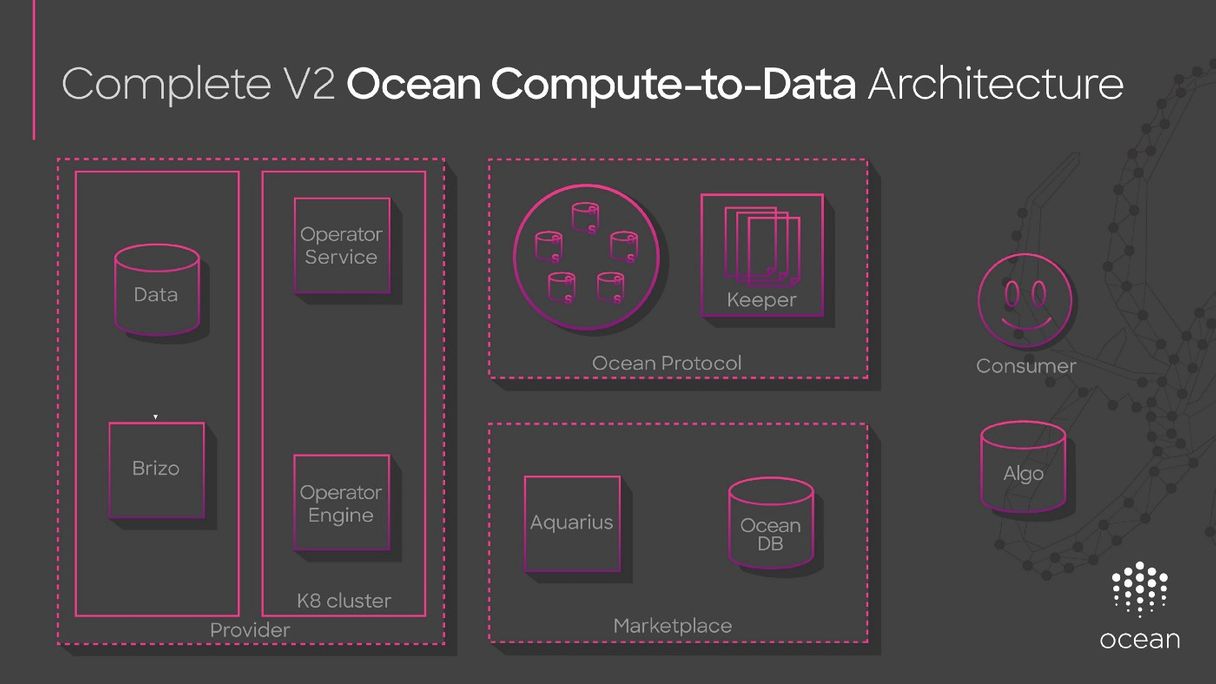
Source: Ocean Protocol
There’s actually no issue in extracting value out of private data. The problem is that people that have private data are very reluctant to share the data because of privacy concern, regulation concerns such as the European data protection regulation under GDPR.
There’s always a difficult choice to be made as on one hand yu want access to large data sets including private data in order to train an AI to improve the AI’s models, improve the business outcomes or the research outcomes in science. However, doing that will hurt privacy and control. For example, large enterprises are worried that their millions of users’ data leaving their premises might fall in the wrong hands and expose them to massive liability risks as well as having a PR disaster. A good example of that is when Equifax was hacked and 147.7 million of American’s credit records was exposed.
Of course, on the other hand you do nothing and therefore no extra value but no privacy concerns.
Ocean Protocol’s “Compute-to-data” enables you to get access to data in a way that it extracts value for your models but at the same time doesn’t have any privacy or control concerns.
Privacy is about information flows, it’s about ensuring that information doesn’t flow everywhere. To extract value out of data in privacy conserving manner can be achieve by having computation running right next to the data for AI eyes only not for humans. Humans never see this data. The data never leaves the premises. From that an AI model is built that can do predictions or maybe simple statistics are done, such as building an average.
The resulting derivative information doesn’t have any privacy or control issues. The data remains secure, it never leaves the owner’s premises. The AI model runs on top of the data and extract insights that don’t impact the data’s privacy or control issues. That’s the heart of the idea of compute-to-data.
This is radically different to the present manner we exchange data as it usually involves a middleman mediating between the person who wants to extract the value from data and the person who has the data. That middleman could steal the data or have their data stolen as was the case with Equifax.
The opportunity is that, what if that mediator is a public blockchain that acts as the middleman to orchestrate those events. A public blockchain would bring in transparency and there wouldn’t be a single centralised entity that owns or controls the data. The public blockchain would help connect the people who are consuming the data with the people with the data.
Ocean is leveraging its access technology so that an entity wanting to run an AI training algorithm can run it next to the data and the blockchain technology is orchestrating it.
Ocean compute-to-data is Ocean’s response to solving the current trade-off between benefits of using the private data and the risks of exposing it. Compute-to-data lets data stay on-premise, while allowing 3rd parties to run specific compute jobs on it, like building AI models. There are multitudes of applications in science, technology, and business contexts because the compute is sufficiently aggregating or anonymizing that the privacy risk is minimized.
Could this have been done with a public blockchain?
Trent recognises that this can be achieved. Sophisticated players can of course talk to each other directly. However, it becomes complicated if they wish to talk to more than one player at the same time. They could of course create numerous relationships one by one but this can rapidly become complicated with significant overheads. The opportunity is to share the data on a data marketplace. With blockchain you can have a trust platform that enables the exchange of value and manage the access rights to the data.
Using and trusting Compute-to-Data
Compute-to-date is a general technology for varying levels of comfortability with AI and other technologies. It can be as simple as computing an average. For example, getting an average of cash flows of offices in different countries for a multinational can be tricky if data can’t leave the offices due to difference privacy rules for certain countries. With compute-to-data an average can be built for each country and summed up locally at head office.

For slightly more sophisticated users a linear regression model can be built using data with a number of variables. Linear regression models, according to Trent, suffices 50-80% of the time when doing AI modelling.
The next step in sophistication are Gaussian process modelling or neural networks.
What is key to understand is that the entity suppling the data knows that the AI training algorithm has been vetted and that it’s not going to basically copy all the data back to the person consuming it. Building an average calculation for example requires only three lines of code. Builders of AI models will be using trusted libraries which would have been vetted by some experts. That’s a very small ask for suppliers of data who don’t need to be AI experts.
Monetization – how is price determined for data?
Ocean has a flexibly approach to pricing of data.
Ocean focuses on providing tools for data providers to make a data asset sellable, so that a data consumer can purchase access to the data. In between Ocean provides technology to build data marketplaces. Price of data in a data marketplace is determined by the people running the marketplace. At the moment data marketplaces comes with a fixed price for data. Ultimately though it will be done in an automated manner where price is determined by supply and demand. Ocean’s next version of data marketplaces will also include price discovery of datasets.
Compute-to-date Example – MOBI
Ocean Protocol is part of the MOBI consortium – the Mobility Open Blockchain Initiative. MOBI is a non-profit smart mobility consortium working with forward thinking companies, governments, and NGOs to make mobility services more efficient, affordable, greener, safer, and less congested by promoting standards and accelerating the adoption of blockchain, distributed ledger, and related technologies in the mobility industry. Chris Ballinger, CEO of MOBI was featured on Insureblocks to talk to us about an “Introduction to the Mobility Open Blockchain Initiative (MOBI)”.
Ocean started collaborating with Chris Ballinger in early 2017, when he was still at Toyota research, for autonomous vehicles, electric cars and car sharing. The problem that exists for autonomous vehicles is that the AI algorithms don’t have enough data to reach the required level of accuracy.
A report by the RAND Corporation states that “Autonomous vehicles would have to be driven hundreds of millions of miles and, under some scenarios, hundreds of billions of miles to create enough data to clearly demonstrate their safety”. This would take Toyota 20 years to reach.
Recognising that some of their way competitors were moving faster in accumulating the data, Toyota asked themselves the question “what if we pooled our data with not just ourselves but with the other big automakers such as BMW, Daimler, Volkswagen, GM, and Ford?” That was the initial idea that Ocean started working on with Chris at Toyota in early 2017 by building a decentralised data exchange for autonomous vehicle data exchange around miles driven. That data exchange was decentralised with no single owner or controller that enabled the buying and selling of datasets.
What Ocean identified is that the automakers weren’t keen around their data leaving their premises. For example, Toyota wasn’t so keen on all of its miles driven leaving their premises for being trained by BMW. This concern was partly privacy and partly control. There was also uncertainty on whether the data had identifiable information, or whether it was monetizable and if you shared it would you lose the ability to monetize it. Because of that uncertainty automakers were reluctant to share the data.
This is where compute-to-data comes in. It enables the automakers to pool their data to build accurate enough autonomous vehicles where privacy can be preserved and controlled. What this means is that Toyota can still build an AI algorithm for their autonomous vehicle that uses data from all of its competitors without their data ever leaving their premises. BMW, Daimler, VW and all the others can do the same.
The way this could work is that Toyota might train its model initially on its data to build a baseline model. To update the weights from its model it could bring in BWM data or VW data. Toyota would build a mini training algorithm that goes into the BMW data to run computations for the mini neural network and send updates to its overall neural network at Toyota. Toyota can then use the same mini training algorithm to reproduce the same computations overs at Daimler, GM and Ford to update the weights on its datasets.
In the end, Toyota gets neural network AI model for driving cars that’s been trained across all the automakers that are part of MOBI while at the same time it has preserved privacy of each of those automakers as the data never left their premises.
Compute-to-data and COVID-19
There are a lot of opportunities for AI models and predictions to help to tackle COVID-19. In China everyone is being tracked and are given a colour code of green, yellow or red. Green meaning you’re clear, yellow means you’ve been in contact with someone who had it and Red means you have coronavirus. This kind of surveillance is one which most people in the West are uncomfortable with.
The question is can we do something similar to China but in a data preserving way? Today we are using AI technology to try and measure COVI-19 but it involves looking into a lot of PII (personally identifiable information).
With compute to data you can achieve that. Trent challenges us to imagine a world where you have access to all of the data across the whole life cycle from sensing and contacting coronavirus all the way through to treatment every step of the way, to ty and prevent things from getting worse. Imagine you have access to all of this data but without seeing any PII, where you can run compute-to-data on all of these data sets in order to get a very holistic view for the whole world with AI trying to prevent each step from getting worse.
All this data of course can also be very useful for health insurers who can use the data to build better actuary models.
Plans for 2020
Ocean had an alpha version of compute-to-data late last year and a beta version earlier this year. The platform is now live with several customers using it in beta.
Compute-to-data is now in v2 and Ocean is working on v3 which will have two new main components: data tokens and incentives.
Data tokens
With tokens you can tokenize insurance contracts or tokenize real estate. There are many applications for which you can tokenize. Once you tokenize something you can think of it like removing friction for building financial assets on top of it. For example, once you have a tokenized insurance contract it can flow through the Ethereum ecosystem, and be traded.
In v1 and v2, Ocean had built a blockchain based technology for access control but it was not tokenized. Part of v3 is to tokenize the access control. For example, today to read the Wall Street Journal you need to have a subscription to access the data. Instead of a subscription you could have a data token that grants you access to the Wall Street Journal’s data. However, you can also have an access token for accessing data from BMW or Toyota or to your own medical records.
Ocean is providing the technology for entities to create their own data tokens and to be able to consume them. Once the tokens are created they can flow through the Ethereum ecosystem.
Similar to the Apple Wallet that can hold your boarding passes for an airplane or your cinema tickets. People also have crypto wallets to store their bitcoins and ethers. Eventually inside the Apple wallet or the crypto wallet you could have data tokens that give you access to products and services such as the Wall Street Journal to give you access to its data. Those data tokens can also be used for identity and KYC purposes. You could use them to prove your identity and your credentials for example your PhD from verifiable credentials.
It can also be used for insurance. For example, you can tokenize your Apple Health app data and give your insurance provider a data token to access that data to give you a lower insurance rate.
Incentives
Incentives is about making incentivising people to make the ecosystem more valuable, whilst they are buying and selling data.
With Ocean people will be able to set up their own marketplaces. They will have a degree of automation as market makers. People can add liquidity to his to buy and sell datasets. For every transaction a transaction fee is charged where a percentage of it is used to reward people who do work in the form of referrals, curation and adding liquidity to reduce slippage.
Spread the love






