

Trent McConaghy grew up on a farm in rural Canada. He did AI research for 20 years including running 2 startups and a PhD. For the last 5 years he has been focused on blockchain and in particular on Ocean Protocol which he has co-founded.. Ocean Protocol is a protocol whose mission is to unlock data for the broad benefit of society. Data is becoming increasingly important and influential throughout the world, ensuring that the opportunities to access data are equalised is the aim of Ocean Protocol.
What is blockchain?
Blockchain at its heart is a technology, just as the internal combustion engine or a computer. The internal combustion engine combined with oil unlocked mobile transport in a big way. Similarly blockchain unloads a whole new set of possibilities that we haven’t seen before. At the very heart, it is simply a database. However its a database with very specific characteristics:
- Decentralised: no single entity owns or controls it
- Immutable
- Concept of ownership if you have the private key to it such as tokens for money like with Bitcoin
- Unlocks incentives – blockchain can be used to shape incentives for human behaviour
What is the data economy?
Trent looks at the token economy as the open version of the money economy. With the money economy we have tokens, currencies, etc. Traditionally these were distributed solely by national governments in opaque ways through the Fed and Central Banks. Whilst this has been beneficial in many ways there were still challenges. Bitcoin opened up the money economy by being permission less, friction free and fully open.
Today there is a data economy, but like the money economy it is very opaque where credit card companies are selling your data, Facebook buying data from 150 organisations to add it to its own data in order to sell you more adds. There already is a data economy where it’s a flow of value and participants in the economy are buying and selling data in a closed and opaque manner. Just as Bitcoin opened up the money economy, ocean is designed to open up the data economy.
AI, the last mile of data
Just like the internal combustion isn’t useful on its own nor is oil useful for its sake, both of them are useful towards machines that are then used for mobility. AI, is the last mile to unlock the value of data. Modern AI really loves data. The more data it receives the more accurate its models become which in turn can create business value. For example AI models used to predict cancer usually use data gathered from 100 individuals. These models can predict cancer from 6 months in or even from stage three. If those AI models were based on orders of magnitude of more data such as over millions of individuals then you could theoretically predict the existence of cancer 6 days into it from very early weak signals. Feeding large amounts of data into AI can help to unlock value and build new applications.
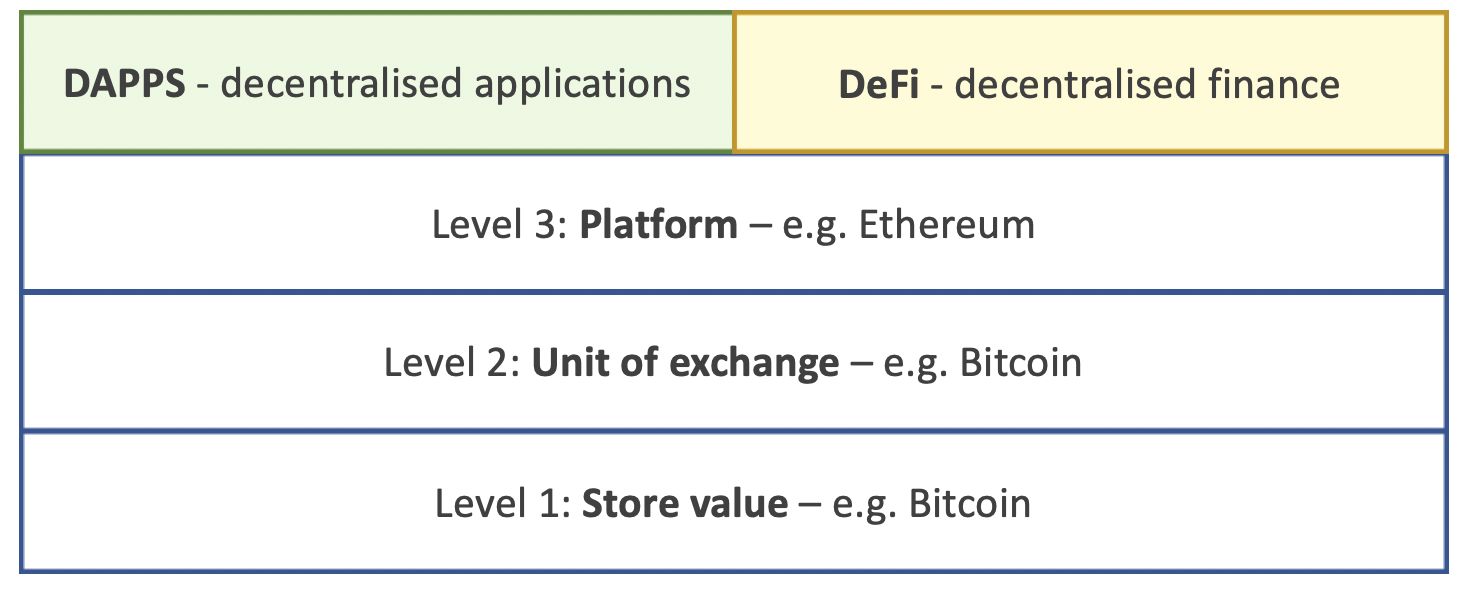
Components of the data economy
Three levels to both the open money economy and to the token economy:
- Base infrastructure (i.e. a store of value)
- Unit of exchange
- Platform to launch and to exchange things
The last mile on top of the platform are the applications.
In the token economy the de factor standard, the unit of exchange, that has emerged is Bitcoin. The platform is Ethereum. On top of the platform you have a set of decentralised applications, DAPPS, running on Ethereum, which represent the kind of last mile in terms of applications. In terms of financial side the last mile are Decentralised finance or DeFi, some use cases of DeFi are for payments, lending, stablecoins, tokenization and decentralised exchange.
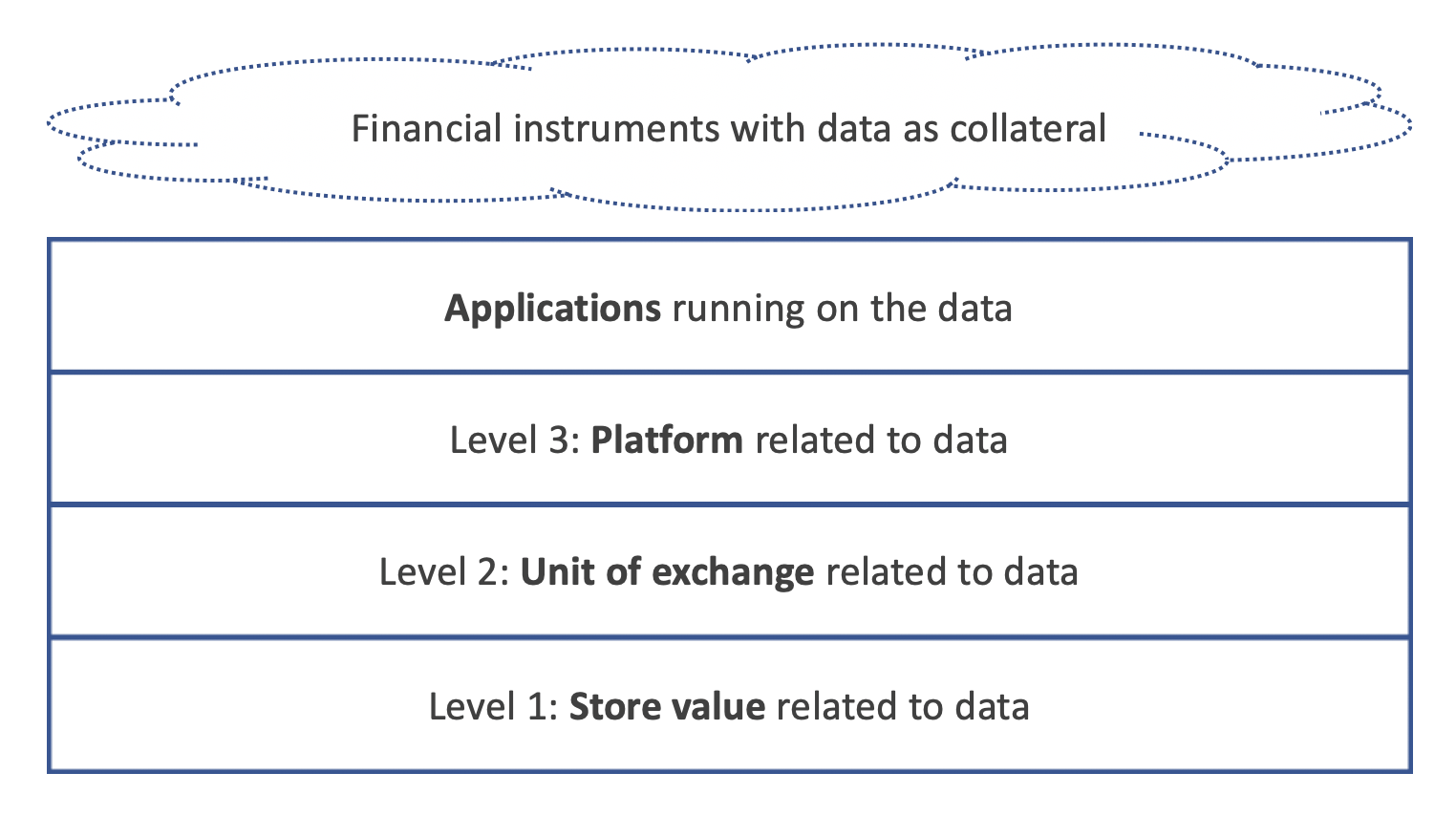
The components of the data economy are very similar in structure to the ones of the open money economy and the token economy. At the bottom level you have a store of value in terms of data, you have a unit of exchange related to data and you have an application platform related to data. One level up you have the last mile were you have the financial instruments that sit on top of this base, where data itself is the collateral. If you can collateralise data then you can get loans against data itself, insurance on data and many more applications.
Example: Connected Life and Parkinson
Connected Life is an organisation based out of Munich and Singapore that is building data models to predict Parkinson. They’ve been working with TUM, the Technical University of Munich to get data from their patients to build those data models. They’ve also been working with NUS, the National University of Singapore to get data from their patients. Because of data privacy laws, GDPR, in Germany, the data can’t leave European soil. Similar laws exist in Singapore. Ideally Connected Life wants to be able to build data models that uses both data sets without breaking those countries respective privacy laws.
With the help of Ocean Protocol they built a data model that update itself form the Singapore data set as well as from the Munich data set, thus ensuring you have a model that has twice as much data. Connected Life is working to extend this test to more hospitals for not only for Parkinson diagnosis, but also for treating and for prevention.
In America a lot of healthcare data is sold to insurance companies and to other providers. So, there’s already value being transferred there. If each piece of data was tokenised and collateralised then you can have financial instruments on top. In due course what this means is that consumers could be incentivised to making their data available. Insurance companies for example could request such data to improve their data training models, for better predication of insurance whilst at the same time consumers are not giving up their privacy.
Ocean Protocol – helping companies embracing the data paradigm shift
connecting the data and the AI expertise
Most large enterprises have big data enterprises. Whether it’s in their infrastructure with Oracle databases, MongoDB and Hadoop to people like Chief Information Officers and emerging Chief Data Officers.
Ocean can simply help those large enterprises solve their data management problems better. For example those that are multinational with offices in various countries they might not be able to share data from one office to the next because of data regulation. Additionally, it is important to recognise that data sometimes needs to stay at company’s premises, it needs to stay private. How do these organisations benefit of these data sets merging as in the above case of Connected Life? The big trick is to bring computational power to the data where it is vetted computational algorithms that are running against the data by applying simple business intelligence and eventually building AI models.
The competitive advantage is data and not AI. Most Fortune 500 companies have a tons of data and they’re wondering what do to with it as they’re concerned about sharing it due to privacy issues and because of the fear of losing control. These companies have been trying to recruit the necessary AI expertise but the vast majority of available AI experts have gone off to work for Google, Facebook and Amazon. It is the combination of data and AI that has led to massive value creation for the Google, Facebook and Amazon’s of this world.
Waymo, is Google’s off shoot autonomous vehicle. Recently it has been valued above $175 billion, which is superior to BMW’s valuation of $42 billion, Volkswagen, $76 billion and Daimler $48 billion combined! The market recognises that the future is in the data.
The question then is how can incumbents unlock the benefits of data? How to spread the benefits of data and spread the benefits of AI? That’s what Ocean Protocol was designed for. Ocean makes it possible for these Fortune 500 companies to access the benefits of AI without compromising their privacy and control.
Ocean makes it easy for AI experts to build models for the benefit of Fortune 500 companies without those companies losing control of the data. So it’s connecting the data and the AI expertise.
Lessons to take from Toyota?
Google’s ambitions in autonomous vehicles goes back to the DARPA Grand Challenge of 2005. This has given them over a decade competitive advantage over the incumbents. The response from the incumbents in the auto industry is maybe instructive for insurance.
Toyota realised that to do autonomous driving they would need 500 billion miles of driving data onto roads which would have taken them 20 years to acquire. Toyota reached out to Ocean Protocol to pool their data alongside GM, Ford, Daimler and others to compete against Waymo and win. Ocean built an autonomous vehicle data exchange and a prototype two years ago. On the back of that Toyota realised that they couldn’t pursue this on their own so Chris Ballinger, who was running the project left Toyota to create a consortium called Mobithat now has over 100 organisations signed up to it including 80% of the world’s auto production. What these organisations have realised is that not a single one of them can win the data game on their own. But collectively they can create massive value by pooling their data in a way that reconcile privacy. That is a lesson insurance amongst other incumbents industries can take note off.
Your turn
Thank you, Trent, for sharing your insights on the data economy. If you liked this episode, please do review it on iTunes. If you have any comments or suggestions on how we could improve, please don’t hesitate to add a comment below. If you’d like to ask Trent a question, feel free to add a comment below and we’ll get him over to our site to answer your questions.
Spread the love






